
Hyper-personalization in retail is an event-driven, real-time personalization strategy that uses unified customer identity, behavioral data, and AI-powered decision engines to tailor individual experiences across digital and physical channels. Unlike traditional segmentation, it responds dynamically to customer actions as they occur.
According to Twilio Segment’s State of Personalization research, 86% of business leaders expect a significant shift from reactive to predictive personalization across industries, signaling that hyper-personalization is moving from marketing experimentation to infrastructure priority.
For IT leaders, this shift requires more than enabling recommendation widgets or campaign automation. It demands a unified customer data platform (CDP), real-time event ingestion, identity resolution, low-latency decisioning engines, API orchestration, and built-in governance controls.
This guide outlines the reference architecture, implementation roadmap, integration layers, and security considerations required to deploy hyper-personalization in retail environments at scale.
Why hyper-personalization is now a data infrastructure initiative
Hyper-personalization in retail is no longer just a marketing capability. It has become a data infrastructure initiative, meaning the systems that support it sit at the core of a retailer’s technology stack.
Historically, personalization was relatively simple. Retailers grouped customers into segments, such as “new customers,” “VIP shoppers,” or “inactive users,” then sent the same promotion to everyone in that group through scheduled email campaigns or periodic promotions.
Today, customer engagement happens continuously across websites, mobile apps, stores, and messaging channels. Each action — viewing a product, adding an item to a cart, visiting a store, or opening an app — generates a signal about customer intent.
Modern retail systems are expected to respond to those signals immediately. A shopper browsing a product might see related recommendations within seconds or receive a follow-up message shortly after leaving the site.
Supporting this type of responsiveness changes the technology requirements. Instead of exporting spreadsheets into marketing tools, retailers now rely on real-time data pipelines that capture customer activity as it happens. These systems feed decision engines that determine what recommendation, offer, or message should appear next.

This shift places new demands on IT teams. Marketing departments want AI-driven recommendations, automated cross-channel campaigns, and next-best-action systems. Executives expect measurable revenue impact. Delivering those capabilities requires infrastructure, such as data ingestion pipelines, customer data platforms (CDPs), identity resolution systems, and scalable cloud environments.
The underlying shift is architectural. Traditional personalization was campaign-based, with scheduled batch messages. Hyper-personalization is event-driven: each customer action becomes an event that flows through ingestion systems, identity resolution services, decision engines, and activation channels.
As a result, hyper-personalization becomes a cross-functional effort:
- IT manages data pipelines, APIs, infrastructure, and system reliability.
- Data science builds and maintains predictive models.
- Marketing defines personalization use cases and performance targets.
- Security and compliance ensure customer data is handled according to privacy regulations.
For retailers, hyper-personalization is no longer a feature that marketing can deploy independently. It requires coordinated investment in data architecture, analytics, and governance across the organization.
Components of a hyper-personalization architecture
Hyper-personalization architecture typically includes five layers: data ingestion, identity resolution, event streaming, intelligence and decisioning, and activation. Together, these layers allow retailers to collect customer signals, interpret them in real time, and deliver personalized experiences across digital and physical channels.
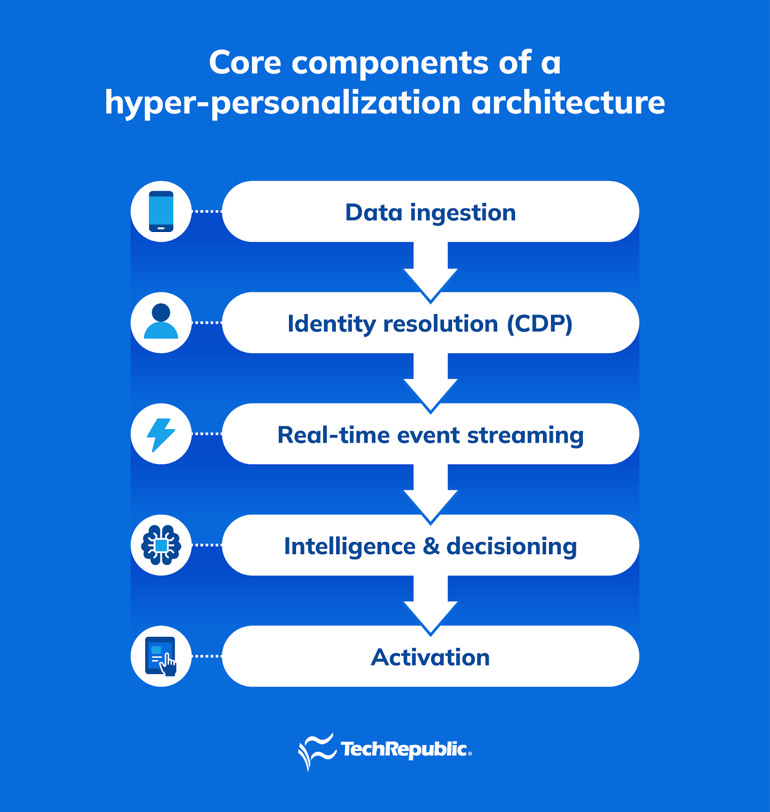
Each layer plays a specific role in turning raw customer activity into actionable insights and personalized interactions.
1. Data ingestion layer
The data ingestion layer collects customer activity from across the retail ecosystem. Typical sources include:
- POS systems
- Ecommerce platforms
- Mobile apps
- CRM systems
- Loyalty platforms
These systems generate both structured data and behavioral signals.
Structured data includes transaction records, product SKUs, timestamps, and loyalty IDs. Behavioral signals include browsing activity, clickstream events, and engagement data from websites or apps.
Retail organizations must also decide how this data enters their systems. Some data is processed in batch jobs, where updates occur periodically, such as nightly database updates. However, hyper-personalization depends heavily on streaming ingestion, where events are processed as they occur.
Streaming pipelines allow retailers to react to events, such as a product view or a cart abandonment instance, in real time, enabling immediate recommendations or follow-up messaging.
2. Identity resolution and customer data platform (CDP)
Once data is collected, it must be tied to a specific customer. This is the role of the identity resolution layer, typically powered by a customer data platform (CDP).
A CDP consolidates data from multiple systems and builds a unified customer profile that combines behavioral history, transactions, and identity attributes.
To do this, the platform stitches together identifiers such as:
- Email addresses
- Device IDs
- Loyalty numbers
- Phone numbers
- Account login credentials
Two approaches are commonly used.
- Deterministic matching links records using exact identifiers, such as a logged-in email address or loyalty account.
- Probabilistic matching uses statistical models to infer connections between devices or sessions when exact identifiers are unavailable.
As third-party cookies disappear, retailers are relying more heavily on first-party data, including authenticated accounts and loyalty programs, to maintain reliable identity resolution.
CDPs can be deployed in two main ways. Enterprise CDPs provide an integrated platform with built-in identity resolution and orchestration. Composable CDP architectures combine data warehouses and specialized tools connected through APIs.
3. Real-time event streaming layer
Hyper-personalization systems rely on event-driven architecture. Instead of waiting for scheduled updates, the system processes customer actions as events.
Examples of common retail events include:
- product_viewed
- cart_abandoned
- purchase_completed
Event streaming platforms process these signals continuously and distribute them to downstream services. This real-time processing allows systems to respond immediately to customer behavior. For example, a product view event might trigger a recommendation update or a follow-up email workflow.
Because these responses must happen quickly, many systems aim for response times below 200 milliseconds to avoid slowing down the customer experience. To maintain consistency, events are structured using predefined schemas that ensure all services interpret the data in the same way.
4. Intelligence and decisioning layer
The intelligence layer analyzes customer data and determines what action to take next.
Common capabilities include:
- Product recommendation engines
- Predictive models
- Purchase propensity scoring
- Next-best-action systems
These models are trained on historical customer behavior and transaction data. Depending on how quickly behavior changes, models may be retrained weekly, daily, or monthly. Retail systems must also monitor model drift, which occurs when predictions become less accurate as customer behavior changes over time.
Decision engines expose their outputs through APIs. When a customer visits a website or opens an app, the front-end system requests recommendations from the decision engine and displays the personalized results.
5. Activation layer
The activation layer delivers personalization to customer-facing systems. Typical activation channels include:
- Ecommerce storefronts
- Email marketing platforms
- Mobile push notifications
- In-store POS systems
- Digital signage
These systems receive outputs from the decision engine through APIs or webhooks.
Personalization outputs may trigger automated emails, update storefront recommendations, or adjust mobile app experiences.
In modern headless commerce architectures, frontend applications request personalization data through APIs before rendering content. This allows retailers to separate customer experience interfaces from backend intelligence systems.
When all five layers work together, retailers can deliver consistent personalization across every channel. If any layer is missing or poorly integrated, delays, inaccurate recommendations, or fragmented customer experiences can occur.
Related: What Is Headless Commerce and Why It Matters for Retail
Reference architecture for retail hyper-personalization
Retail hyper-personalization systems follow a consistent flow: data is collected from multiple sources, unified into customer profiles, processed as real-time events, analyzed by ML models, and delivered to customer channels through APIs.
At a high level, the architecture looks like this:
Data sources → CDP → Event streaming → ML decision engine → API gateway → Customer channels
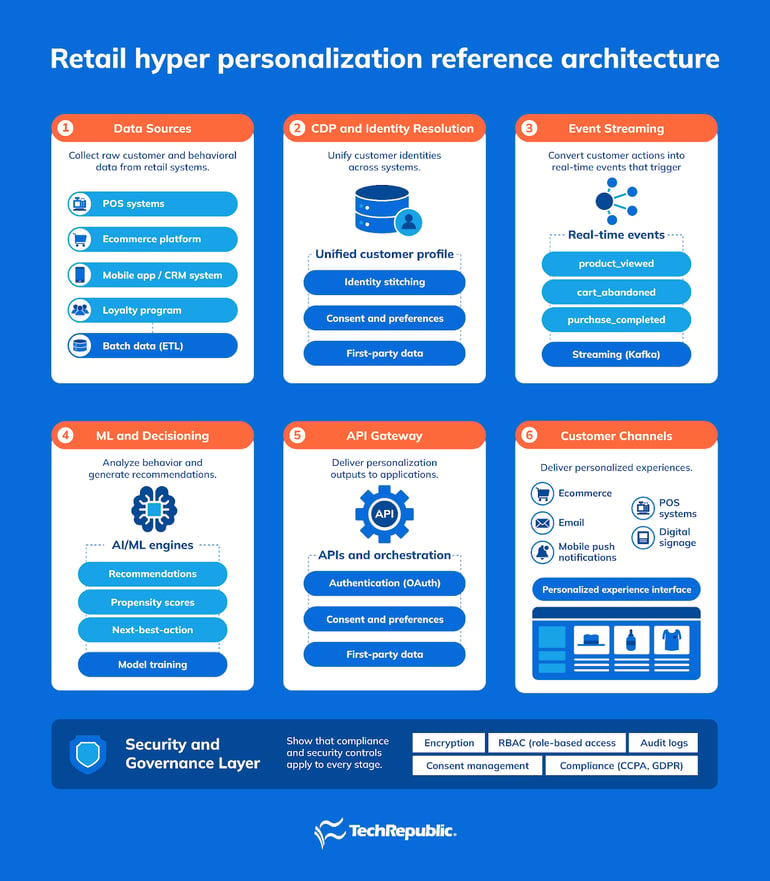
Each stage transforms raw customer activity into personalized experiences.
End-to-end architecture flow
1. Data sources
Personalization begins with collecting signals from across the retail ecosystem. Typical data sources include POS systems, ecommerce platforms, mobile apps, CRM platforms, and loyalty systems.
These systems generate two types of data. Transaction data includes purchases, product identifiers, and timestamps. Behavioral data includes browsing activity, cart additions, product views, and app interactions.
Together, these signals form the foundation of the personalization pipeline.
2. CDP and identity resolution
Once data is collected, it must be tied to a specific customer. This is handled by the customer data platform (CDP) and identity resolution layer.
The CDP consolidates data from multiple systems and builds a persistent customer profile. For example, a shopper who browses on mobile, purchases online, and visits a physical store should still appear as a single customer profile in the system.
3. Event streaming
Customer actions are then published as events in real time. This approach is known as event-driven architecture, where every user interaction generates a signal that flows through the system.
Streaming platforms distribute these events to downstream services so personalization systems can respond immediately.
4. Machine learning and decision engines
The next stage analyzes the event data and determines the appropriate response.
Machine learning models and decision engines evaluate customer profiles and recent behavior to generate outputs such as product recommendations, purchase propensity scores, or next-best actions.
These decisions determine what content, offer, or message the customer should see next.
5. API gateway and orchestration
The decision outputs are then delivered through an API gateway, which acts as the interface between backend intelligence systems and customer-facing applications.
The API gateway manages authentication, traffic routing, rate limiting, and monitoring. It ensures that ecommerce sites, mobile apps, and marketing tools can safely and consistently retrieve personalization decisions.
6. Customer channels
Finally, personalization is delivered through customer-facing channels. These may include:
- Ecommerce storefront modules
- Triggered email campaigns
- Mobile push notifications
- In-store POS prompts
- Digital signage
At this stage, the system converts data insights into actual customer experiences.
Deployment models
Retailers deploy hyper-personalization systems in different ways depending on their infrastructure, legacy systems, and performance requirements.
Deployment models
Retailers deploy hyper-personalization systems in different ways depending on their infrastructure, legacy systems, and performance requirements.
1. Cloud-native deployment
In a cloud-native architecture, most services — data ingestion, event streaming, machine learning, and activation — run in a public cloud environment such as AWS, Azure, or Google Cloud.
This model simplifies scaling and allows teams to use managed services for data processing, machine learning, and infrastructure monitoring. It also reduces the operational overhead associated with maintaining on-premises systems.
2. Hybrid architecture
Many retailers operate in hybrid environments because store systems and POS infrastructure often remain on-premises.
In hybrid deployments, in-store systems continue running locally while key data is synchronized to cloud pipelines. The cloud environment then handles streaming, analytics, and personalization decisioning.
This approach allows retailers to modernize personalization capabilities without fully replacing legacy store infrastructure.
Edge personalization vs centralized decisioning
Another architectural decision involves where personalization decisions are made.
In centralized models, decision engines run in a core cloud environment. Customer channels request recommendations through APIs. This approach simplifies management but can introduce latency if network performance is poor.
In edge personalization models, some decision logic runs closer to the user or store location. This reduces response times and can improve performance for high-frequency interactions.
Many retailers use a hybrid approach: centralized intelligence systems combined with edge caching to deliver faster responses for commonly requested personalization data.
Once the architecture is defined, IT teams can begin implementing hyper personalization capabilities through a structured rollout.
Step-by-step implementation roadmap for IT teams
Implementing hyper-personalization requires more than deploying a single tool. IT teams must build the supporting data and decision infrastructure in phases.
Most retail implementations follow six steps: auditing data sources, establishing identity and customer profiles, enabling real-time data pipelines, integrating decision engines, activating personalization across channels, and implementing monitoring and governance.
Step 1: Conduct a data audit and schema mapping
Start by identifying every system that generates customer data. This typically includes POS systems, ecommerce platforms, mobile apps, CRM systems, and loyalty programs.
Once these sources are identified, standardize the data schemas used across systems. A schema defines how data fields, such as customer IDs, product identifiers, timestamps, and events, are structured. Consistent schemas allow systems to exchange data reliably.
During this step, teams should also identify identity gaps. Common issues include anonymous POS purchases, missing loyalty identifiers, or incomplete ecommerce profiles. These gaps make it difficult to link activity across channels and limit personalization accuracy.
Step 2: Deploy or configure a customer data platform
The next step is implementing the system responsible for building unified customer profiles.
Retailers can deploy a vendor CDP or create a composable architecture using their data warehouse and integration tools. Regardless of the approach, the goal is to consolidate customer data into a single profile.
At this stage, IT teams must define identity resolution rules. These rules determine how identifiers such as email addresses, loyalty IDs, device IDs, and phone numbers are linked to the same customer.
Data governance policies should also be established early. These policies define who can access customer data, how long data is retained, and how consent preferences are stored and enforced.
Step 3: Implement real-time event ingestion
Hyper-personalization relies on event-driven data pipelines that capture customer behavior as it happens. IT teams should configure a streaming pipeline that ingests and distributes key behavioral events across systems.
Monitoring latency is critical at this stage. If events move slowly through the system, personalized responses will arrive too late to influence customer behavior.
Step 4: Integrate AI decision engines
Once events and customer profiles are available, retailers can introduce machine learning decision systems.
IT teams must configure inference endpoints, which are APIs that allow other systems to request predictions in real time.
Before deployment, teams should validate that model outputs are relevant and stable. Recommendation quality should be tested, propensity scores should align with actual customer behavior, and fallback logic should be implemented for situations where customer identity is unknown.
Step 5: Activate personalization across channels
After decision systems are operational, the next step is connecting them to customer-facing platforms.
Ecommerce sites integrate personalization APIs into storefront modules and checkout experiences. Marketing automation platforms use the same outputs to trigger emails, SMS messages, and push notifications.
At this stage, performance testing becomes important. Systems should be tested under realistic traffic conditions to ensure APIs respond quickly and reliably.
Many activation failures occur because of rate limits, slow API responses, or integration errors between services.
Step 6: Establish monitoring and governance
The final step is operational oversight. Hyper-personalization systems require monitoring across ingestion pipelines, machine learning services, and activation channels to ensure uptime and reliability.
IT teams should implement alerts for issues such as missing events, schema changes, or identity resolution failures. Governance processes must also address privacy compliance. Retailers must support consent tracking, marketing opt-outs, and data deletion requests in accordance with privacy regulations.
Without monitoring and governance, personalization systems may function technically but still expose the organization to operational or regulatory risk.
Build vs buy: Technology stack decisions
Choosing a hyper-personalization stack requires balancing control, cost, scalability, and integration complexity. Retail IT teams must decide which capabilities to build internally and which to adopt through managed platforms.
Enterprise CDPs vs composable stacks
Enterprise CDPs provide unified identity resolution, customer profiles, and orchestration within a single platform. This approach simplifies implementation and reduces integration overhead, but it may limit customization and create long-term vendor dependencies.
Composable architectures take a different approach. Instead of relying on a single platform, organizations combine data warehouses, identity resolution tools, and orchestration services through APIs. This model provides greater flexibility but requires stronger internal engineering capabilities and more operational oversight.
In-house ML vs managed ML services
Machine learning capabilities can also be built or outsourced.
In-house ML infrastructure offers maximum control over model design, training pipelines, and optimization. However, maintaining these systems requires dedicated data science and engineering resources.
Managed ML services simplify deployment by providing prebuilt infrastructure for model training, deployment, and monitoring. This reduces operational complexity but may limit customization for specialized use cases.
Monolithic commerce vs headless commerce
Commerce architecture also affects personalization capabilities.
Monolithic commerce platforms bundle frontend and backend systems together, which can limit how personalization services integrate with customer experiences.
Headless commerce separates the frontend presentation layer from backend services. This architecture allows ecommerce sites, mobile apps, and other interfaces to request personalization data through APIs, making it easier to integrate recommendation engines and decision systems.
Related: Composable Commerce vs Headless Ecommerce: How to Choose the Right Approach
Key decision factors
When evaluating personalization infrastructure, IT leaders should consider:
- Total cost of ownership
- Scalability under peak retail traffic
- Integration effort and available engineering resources
- Vendor ecosystem maturity and long-term support
The right approach depends on the organization’s size, technical maturity, and growth plans. For many retailers, a hybrid strategy — combining managed platforms with selectively built components — offers the best balance between speed and flexibility.
